






Why should you care about streams?
On the modern web platform, many interesting features appear which enable new functionality which were not previously possible, for example, Web Bluetooth, Background Sync & Web VR. For new features in JavaScript specifically, many are just syntactic sugar for things you could already do in an alternative way, like template literals, arrow functions & the spread operator. There is an important characteristic about those previous three examples: they benefit the developer (better productivity and code maintainability) more than the user. Contrast this with the Streams Specification: using streams changes the way you read, write & process data. Depending on your use case, code complexity can increase.
However, streams can enable efficient processing of data leading to better memory performance, which can benefit the user because:
- There is less memory being consumed, saving more resources for other applications
- Improved battery life on portable devices
- There is a faster/snappier experience when using the web application

A note from the author: Never having studied computer science, I always thought concepts like streams and buffers were concepts I would never touch or experience directly when working on the web. Streams are now a living standard and the primitives already exist in some modern browsers. Not only are they necessary for me to learn, but in doing so, I can craft better experiences for my users.
Node.js vs. the Streams Specification

You might assume the streams we are referring to are the same as streams in Node.js. If you haven’t worked with Node.js streams directly, you may know of them through certain build pipelines like Gulp, which heavily uses streams. The version of streams we refer to in this article are an official specification from the WHATWG (Web Hypertext Application Technology Working Group).
While the Streams Specification and Node.js streams share similar concepts, there are some differences which are documented in the Streams FAQ.
A brief overview of streams
Streams enable you to consume pieces of data. Rather than loading all data into memory (RAM), you can read data piece by piece. This enables your web app to improve its memory usage, which can be noticeable on under-powered devices.
Streams are useful for representing underlying sources of I/O data, such as data from the network. Streams enable memory efficient software because when you are finished consuming a chunk, the garbage collector can clear that specific chunk from memory.
There are only two types of streams in the WHATWG specification, readables and writables. They have certain characteristics.
Characteristics of streams

- They can have the concept of a start and an end
- They can be cancelled – To cancel a stream is to signal a loss of interest by readable stream reader using the
cancel()method - They can be piped – To pipe a stream is to transmit chunks from a readable stream into a writable stream
- They can be forked – To fork a stream is to obtain two new readable streams using the
tee()method - They store values internally for future consumption
- A stream can only have a single reader, unless the stream is forked
Use cases of streams
The WHATWG Streams specification also covers this topic, but generally, streams are a suitable replacement for consuming one large buffer representing I/O data. Video is a practical example, instead of downloading a video over the network and processing that video as one large buffer, you can consume the video in chunks, applying video processing (like decoding or video effects) to each chunk sequentially.
As another example, consider you have a 100 KB text file to display to the user in a web page. If the file is downloaded via background HTTP Request, your code might look like this:
const url = 'https://jsonplaceholder.typicode.com/photos';
const response = await fetch(url);
document.body.innerHTML = await response.text();

In the above screenshot, the network download is represented by a grey rectangular bar, it contains the text photos. Notice that rendering can only begin once the network download has completed in its entirety.
In the screenshot below, the network resource is downloaded but consumed incrementally using the Streams API, which the Fetch API makes use of through a streaming response body.

In the above screenshot, notice that rendering begins even when the download is not complete. This benefits the user as they can start to consume information earlier than without streaming.
Readable Streams
Data flows out of a readable stream. A readable stream can be consumed by a reader, of which there can only be one.
A readable stream includes the concept of an underlying source, the source of internal data. For an outside consumer to receive chunks from a stream, the chunks would originate from the underlying source as the underlying source is where chunks are enqueued.
To recap, when you enqueue a chunk of data, it remains in the underlying source. An outside consumer can consume these chunks.
If data is enqueued into a readable stream regardless of whether it is being consumed by a consumer, this is a push source. If data is only enqueued into a readable stream when a consumer requests data, this is a pull source.
To consume a readable stream, there is only a single concept you need to know about, and that is a reader. A reader can be obtained from a readable stream:
const reader = readableStream.getReader();
reader.read();
If you would like to try out a practical example of consuming a readable stream, here is one you can paste into the console panel of Chrome DevTools:
(async () => {
const response = await fetch(location.href);
const reader = response.body.getReader();
const chunk1 = await reader.read();
console.log(chunk1);
})();
The above code snippet does the following:
- Fetch the current page contents via the Fetch API
- Opens a reader of the response body (The response body is a readable stream)
- Reads (or consumes) one chunk from the reader
- Logs the chunk to the console
If the response body is not a readable stream, a readable stream reader would not be able to consume data from the response body.
Tip: As the response body is a readable stream, you can inspect response.body.constructor.prototype to log interesting methods & properties of the readable stream class.

Notice in the screenshot above, there is also a cancel method on the readable stream prototype. As you might guess, this cancels a stream which enables a powerful behaviour if you consider the ability to cancel a network request after consuming just a few chunks from it.
The tee() method (also see the Tee command) closes the stream and then creates two new streams. Memory efficiency is achievable when a stream can only be consumed once, this is why single-use stream readers are the default behaviour. You cannot access two readers from a single readable stream. You may also note there is a locked property on the readable stream class. This specifies whether or not an active reader exists.
const stream = new ReadableStream()
console.log(stream.locked) // false
const reader = stream.getReader()
console.log(stream.locked) // true
reader.releaseLock()
console.log(stream.locked) // false
Constructing a readable stream
So far, we have primarily focused upon consuming an existing stream. For many use cases, that may be all you need. However, you can also construct a readable stream which can be consumed by readable stream readers.
To construct a readable stream, consider the following example:
const stream = new ReadableStream({
start(controller) {
controller.enqueue(1);
controller.enqueue(2);
controller.enqueue(3);
controller.close();
}
});
Note: The readable stream constructor accepts an object, that object can have methods including pull() and cancel(), however for demonstrative purposes, only the start() method is shown.
As an exercise, now that you can create a readable stream, try to also consume it.

As for the reader itself, it contains a few other methods in addition to read(). These include:
cancel()– Cancels the stream to signal a loss of interestreleaseLock()– Disconnects the active reader from the stream. This allows a new reader to be obtained from the readable stream
Reminder: A readable stream reader is not identical to a readable stream. A readable stream represents a source of data and can be programmatically created. A readable stream reader is an object which is obtained from a readable stream, and can read chunks from the readable stream it was obtained from.
The stream controller
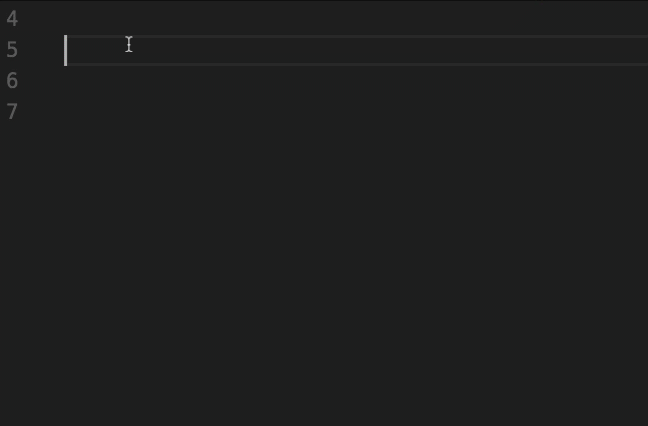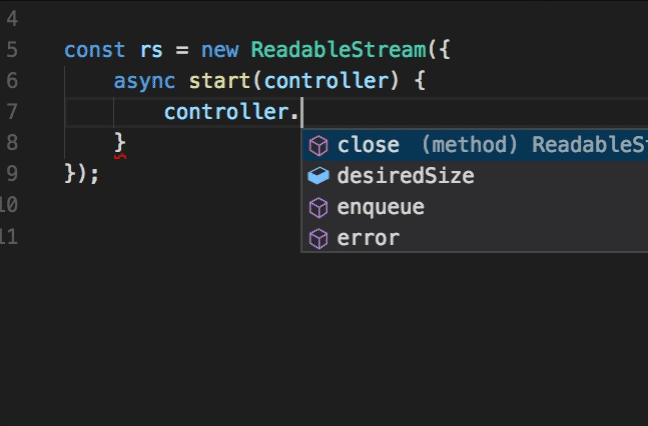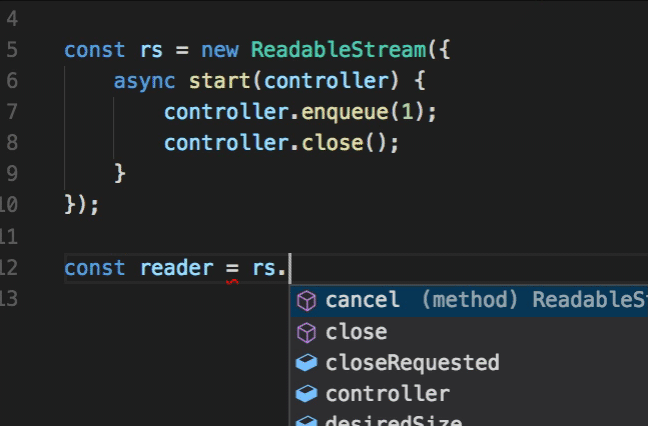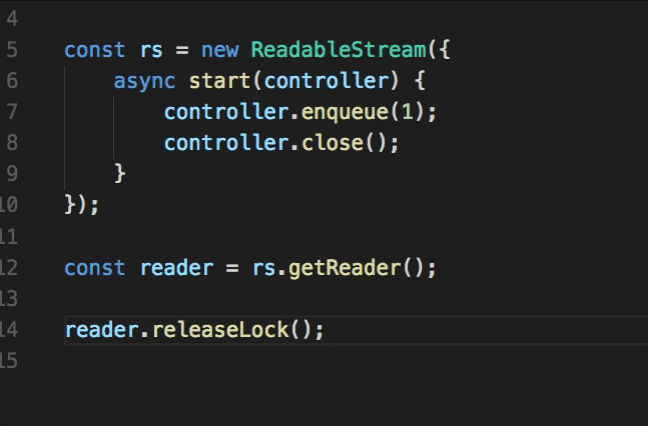
A readable stream controller contains methods which provide control over the internal queue of a readable stream. You can enqueue data into a readable stream through the enqueue() method part of the controller object.
You may recall, from the earlier code example of constructing your own readable stream, a controller argument is passed into the start method.
const stream = new ReadableStream({
start(controller) {
controller.enqueue(1);
},
pull(controller) {
controller.enqueue(2);
controller.close();
}
});
There are a few characteristics of the controller:
- The controller is also passed into the
pull()method - The controller offers an interface to enqueue data, or close the stream
- The controller exposes a few methods, two of which are: controller.
enqueue()and controller.close() - If an outside consumer continues to call reader.
read()and the stream does not have enough queued data in the underlying source, yourpull()method is invoked
Inside a pull() method, your stream has the option to enqueue more data, close the stream, or do nothing. If you proactively enqueue data from within the start() method, your stream resembles a push source. You may wish to proactively enqueue data if you’re certain it will all be read by a consumer.
If you only enqueue data into the stream when then pull() method is invoked, your stream resembles a pull source. It’s useful to enqueue data only as and when it’s needed since the process of acquiring data can itself be computationally expensive or require large payloads to be downloaded over the network. Since a consumer is able to cancel a stream, or simply not read remaining chunks, enqueuing data chunks as and when it’s needed is preferable to avoid potentially wasted bandwidth.
Writable Streams
A writable stream represents a destination for data. When you write to a writable stream from a writable stream writer, data eventually ends up into the underlying sink. An underlying sink is an internal queue of data which a writable stream contains.
If chunks are written into a writable stream at a faster rate than which the stream can process, the chunks are queued up internally within the writable stream before they enter the underlying sink one by one. Chunks are unqueued based on the success of a previous write to the underlying sink. The stream implementation ensures a write operation to the underlying sink can only be called only after previous writes have succeeded.
Code which writes into a writable stream is known as a producer which offers several capabilities. A producer can abort a stream if it wishes to discard chunks of data not yet written to the underlying sink, often to conserve memory. A producer may also wish to abort a stream, putting the stream into an errored state that can be caught in application source code and used to update the user.
A producer can obtain a writer (via getWriter()) in the same way a consumer can obtain a reader via the getReader() method of a readable stream.
| Feature | Readable Stream | Writable Stream |
|---|---|---|
| Data transmission | getReader() |
getWriter() |
| Data transmission name | Consumer | Producer |
| Internal store | Underlying source | Underlying sink |
| Method to signal a loss of interest | cancel() |
close() |
| Piping | Is piped from | Is piped into |
A writable stream can only have one writer at a time. You can call the locked property of the stream to discover if the stream is locked. To release the writer’s lock on the writable stream, simply call: writer.releaseLock().
Piping
A readable stream can be piped into a writable stream. Piping enables you to pipe inputs into outputs, and transform chunks along the way. Piping is useful when you wish to consume a single source of data, and pipe chunks of the data into various transformations, in order to reach a single output.
As a practical example, imagine downloading a large encoded video file over the network. Rather than waiting for the entire video to download so you can decode & play the video, you can pipe chunks of the video into a video decoder stream. Each time a new chunk is downloaded, it is decoded, and then played to the user.
In the code example below, the following steps occur:
- A new readable stream is created
- The readable stream is initialised with three chunks of data
- A new writable stream is created
- The writable stream is piped into the readable stream
- The result of the piping operation returns a promise. This is waited upon before code execution continues
You can find this example on GitHub.
const readableStream = new ReadableStream({
start(controller) {
controller.enqueue(1);
controller.enqueue(2);
controller.enqueue(3);
controller.close();
}
});
const writableStream = new WritableStream();
// This examples pipes the data from a readable stream, into a writable stream.
await readableStream.pipeTo(writableStream);
console.log('Piping has finished');
Backpressure
When you pipe a readable stream into a writable stream, you form a pipe chain. The speed at which data flows from one stream into another stream can be too fast for chunks to be processed by the receiving end of a chain. Streams offer a powerful feature known as backpressure. Backpressure is the process of sending a stop signal backwards through a pipe chain, it is based on the internal queues of a writable or readable stream. Backpressure is covered in greater detail in the Streams specification.
As a brief example, observe the following code:
You can find this example on GitHub.
const countStrategy = new CountQueuingStrategy({
highWaterMark: 2
});
const writableStream = new WritableStream({}, countStrategy);
const writer = writableStream.getWriter();
console.log(writer.desiredSize); // 2
writer.write('1');
console.log(writer.desiredSize); // 1
writer.write('1');
console.log(writer.desiredSize); // 0
await writer.write('1'); // Notice the await keyword
console.log(writer.desiredSize); // 2
The writable stream is created with a ‘high water mark’. This mark is compared against the total size of all chunks in the internal queue, and is then used to determine the desired size.
There are a few points of interest to discuss here, based on the code above:
- An instance of a Count Queuing Strategy is created. This instance defines a high water mark which specifies the maximum total size of all chunks in a queue
- A writable stream instance is created. During creation, the count queuing strategy created in step #1 is applied to the writable stream
- A writer is obtained from the writable stream
- The code then demonstrates how a producer (the writer created in step #3) can observe the desired size
- Writes to a writable stream writer return a promise. This can be used with async/await. The code example demonstrates awaiting for a write to complete successfully
- The desired size of the stream increases after step #5. Contrast this with previous write examples in the code snippet where write calls are rapidly invoked without awaiting for their result
Code examples
Constructing a readable stream and consuming it
This example demonstrates creating a readable stream and initialising it with three chunks. The consumer (the readable stream reader) is able to consume chunks of data one by one. Notice the pull method enqueues more data. The benefit this approach serves is that the consumer is able request data at a suitable time, compared to the approach of receiving all data at once, and it being left to the consumer to split data into manageable chunks.
You can find this example on Github.
const stream = new ReadableStream({
start(controller) {
controller.enqueue(1);
controller.enqueue(2);
controller.enqueue(3);
},
pull(controller) {
console.log('Data was pulled from me!', controller);
controller.enqueue(4);
controller.enqueue(5);
controller.enqueue(6);
controller.close();
},
cancel(reason) {
console.log('Stream was cancelled because: ', reason);
}
});
const reader = stream.getReader();
console.log(await reader.read());
console.log(await reader.read());
console.log(await reader.read());
console.log(await reader.read());
console.log(await reader.read());
console.log(await reader.read());
console.log(await reader.read());
Streaming with the Fetch API
This example executes a network fetch to a text file. Progress updates are displayed on each chunk which is downloaded. In this particular example, progress updates are added to the page per chunk download, however as an exercise, you can modify this example to write the textual representation of the chunk to the page.
The benefit received from displaying progress updates on the page on each chunk download can include:
- Expectations are managed as the end-user is aware of progress, and estimated time remaining
- Perceived performance is increased as updates are streamed incrementally to the page, therefore the user is able to consume information at a quicker point in time
You can find this example on Github.
const url = 'file.txt';
const response = await fetch(url);
const reader = response.body.getReader();
const contentLengthHeader = response.headers.get('Content-Length');
const resourceSize = parseInt(contentLengthHeader, 10);
async function read(reader, totalChunkSize = 0, chunkCount = 0) {
const {value: {length} = {}, done} = await reader.read();
if (done) {
return chunkCount;
}
const runningTotal = totalChunkSize + length;
const percentComplete = Math.round((runningTotal / resourceSize) * 100);
const progress = `${percentComplete}% (chunk ${chunkCount})`;
console.log(progress);
document.body.innerHTML += progress + '<br />';
return read(reader, runningTotal, chunkCount + 1);
}
const chunkCount = await read(reader);
console.log(`Finished! Received ${chunkCount} chunks.`);
Code observations
In this section, we mention four existing implementations of streams through an exploratory perspective.
- WHATWG reference implementation
- Dojo 2 streams implementation in TypeScript
- Chrome & Opera implementation of streams
- Safari implementation of streams
When learning about modern web platform features or JavaScript APIs, it’s common to use tutorials and live demos as reference material. A lesser known technique of grasping a new topic is to scan through existing implementations:
With the Streams API, there are several open source implementations, as well as preliminary native browser implementations.
WHATWG Reference Implementation
Link: https://github.com/whatwg/streams/tree/master/reference-implementation
To cherry pick just one example, take a look at readable-stream.js. It contains an implementation of a Readable Stream. It defines a getReader() method on the class which we discussed earlier. Within the reference implementation, there are other files of interest:

The W3C Web Platform tests contains a rich suite of tests for conformance with the streams specification
Dojo 2 Streams Implementation in TypeScript
Link: https://github.com/dojo/streams
There is an implementation for the Streams API written in TypeScript which is available as a Dojo 2 package. The codebase is well documented and well tested. As it’s using TypeScript, it can also be helpful to read through the Interfaces to understand the public API for a particular class. TypeScript also offers code editor enhancements, which when combined with a new API, can make writing code a smoother process.
There is also an implementation of a Transform Stream which is part of the Streams API specification, however it is not yet implemented in modern browsers due to in-progress specification work.
In the file src/ReadableStream.ts, you can take note of the usual getReader method. You can also observe the unit test which ensures a stream is in a locked state when a reader is active.
Note: The WHATWG Streams Specification goes through frequent changes, so third party reference implementations can spend a lot of time just to keep up. The Dojo team are exploring updating Dojo/streams to match the latest version of the Streams API.
Chrome & Opera implementation of streams
Link: https://github.com/nwjs/chromium.src/tree/nw25/third_party/WebKit/Source/core/streams
Under the hood, large parts of browser internals are written in the C++ language, however increasingly, more modern web platform features are being developed, partially, in JavaScript.
Here is the getReader() method on the readable stream class.
Safari implementation of streams
Link: https://github.com/WebKit/webkit/blob/master/Source/WebCore/Modules/streams
The WebKit implementation includes interface files which gives a convenient hint as to what API a class exposes, for example, here’s the interface for a readable stream.
Here is the getReader() method on a readable stream class.
While on the subject of code implementations of JavaScript streams, it’s worth a mention that Node.js readable streams exist here: https://github.com/nodejs/readable-stream.
Observables
Observables share similar concepts to streams. For example, they also have the concept of consuming chunks over time. Dojo 2 Core includes an implementation of observables. Notice the similarity to the Fetch API + Streams that observables demonstrate:
const response = await request('file.txt');
response.data.subscribe(chunk => {
// do something with chunk
});
Note: The above code example uses Dojo 2 core.
From the same Dojo 2 core repository, notice the observables tests which provide an excellent resource to acquaint yourself with the proposed ES.Next Observables API. For example, this observable concatenation test demonstrates how to:
- Merge observables
- Subscribe to a sequence of values from a collection
The Dojo implementation of observables are offered as a shim within dojo/shim, and offers an interface which can be studied.
The Streams FAQ has a section on how streams relate to observables. One point to note as mentioned in the spec: observables do not include the concept of backpressure and are consequently not the best choice for I/O, such as writing to disk, or reading from the network.
Further Reading
There is substantial existing material available about streams. Here’s a collection of resources including code examples, blogs, guides, API documentation & browser implementations.
- Practical examples of using Node.js streams
- Chrome Status
- MDN Documentation
- Web Platform Tests for Streams
- Reference Implementation (transcription of the spec into JavaScript)
- Frequently Asked Questions on Streams
- An implementation of Streams in TypeScript
- The Fetch API specification in relation to Streams
- The Chrome & Opera (Blink) implementation
- Safari (WebKit) implementation
- Fetch API + Streams Live Demo
- Microsoft Developer Network document on Streams
- Edge Support for Streams
- 2016 – the year of web streams
Conclusion
JavaScript streams provide a powerful and flexible way to manage large sources of data in a memory efficient way. You can already experiment with JavaScript streams in Chrome, Edge, Opera & Safari. Once you are comfortable with consuming an existing stream (reminder: the Fetch API response body offers a readable stream), you can create your own streams from scratch.