






How often have you wanted to yell at your computer or phone? What if your device could save that tirade as a text in an email or note you could review in the future, a memento of your favorite outbursts? Or, maybe you want to provide your users a more hands-free experience, with alerts that also speak to you. Or you simply want to add a clean voice-to-text component to your application. The Web Speech API provides developers with a tool to accomplish all of this!
You can do two things with the Web Speech API: speech recognition and speech synthesis. So you can speak to your apps, or they can speak to you. This of course provides an entire avenue of ways you can leverage the API to provide interactive speech in your applications!
The case for voice
In today’s modern world, you likely use voice-activated technology on a regular basis. Whether you are asking your Google box to play your favorite drinking song, asking Alexa how to spell a word for your child’s homework, or requesting your phone to calculate the tip for your pizza delivery, voice interaction has become almost commonplace in our lives.
The difference here is that most of these applications are most likely not running on a web app, but from a native app of the device. You might be surprised what you could do in a web app with the Web Speech API.
Speech to text
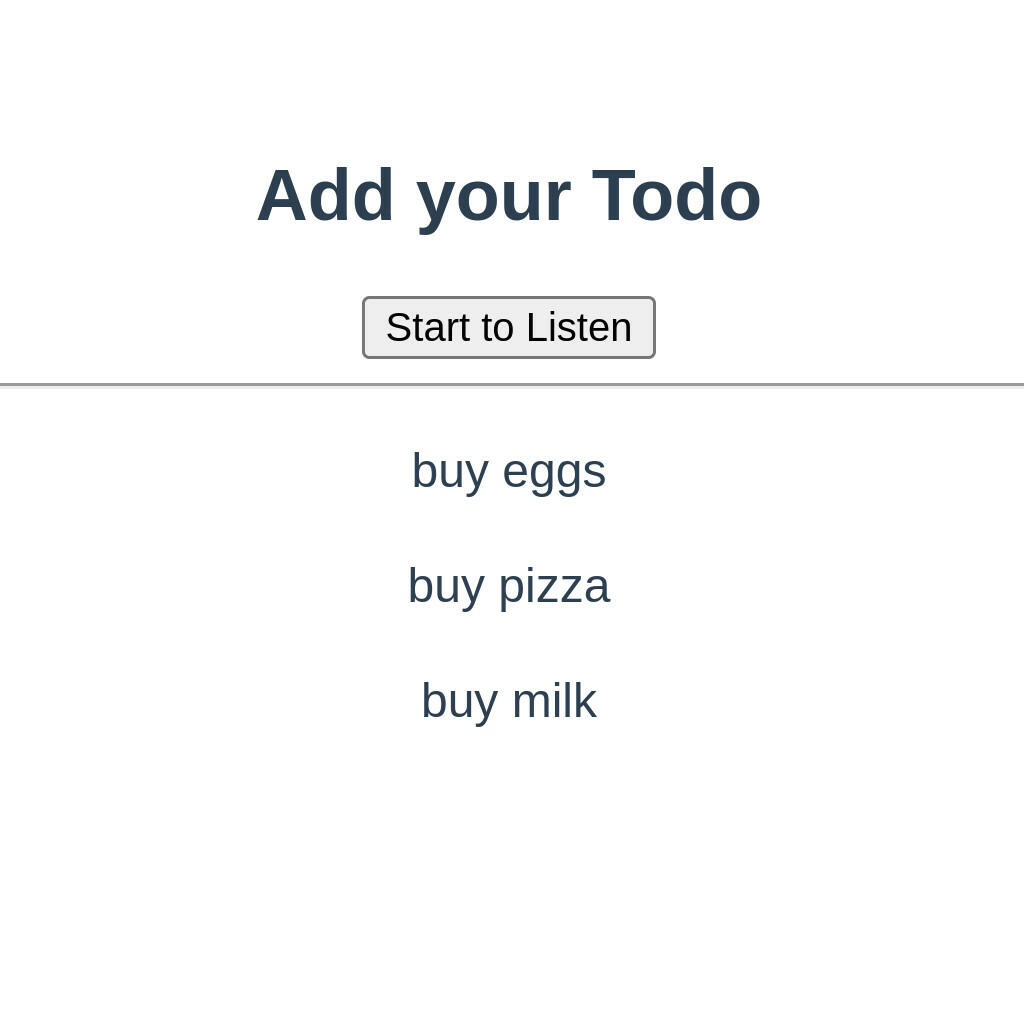
One useful application could be a hands-free Todo application. At most you might want to push a button, speak a phrase, and add it to your Todo list. Let’s talk a little bit about how that can work.
- Click a button to start listening.
- Parse the result from the Web Speech API.
- Add parsed text to the page as a Todo item.
The Web Speech API provides a SpeechRecognition interface. It’s important to note that it can be called webkitSpeechRecognition in Chrome and Safari or SpeechRecognition in other browsers.
Please note, as stated in that documentation, Chrome will use an external server to process your audio, which could be a privacy concern. For this reason, some browser vendors, like Brave have disabled this feature. Safari, however, will process speech.
const SpeechRecognition =
window.SpeechRecognition || window.webkitSpeechRecognition;
const recognition = new SpeechRecognition();
recognition.addEventListener("result", (event) => {
// Pluck result from the event
const result = event.results[0][0].transcript;
// Create a new Todo Item
const todo = createTodo(result);
// Add Todo to page
todo && list.appendChild(todo);
recognition.stop();
});
btn.addEventListener("click", () => {
recognition.start();
});
We can create an instance of SpeechRecognition, and listen (pun not intended) for the result event. There are a number of events we can interact with, but for now, we can focus on the result, as that is what we are interested in. The event will return an array of results that contains an array of SpeechRecognitionAlternative objects. I know that’s a mouthful, but the important part to know is the “transcript” property that contains the recognized text. It will also provide a confidence score, so if you are not happy with the confidence of the result, you can ask the user to repeat the phrase. This could be a lot of fun as an April Fools prank on a sibling by requiring a confidence level of 0.99. Once we extract the recognized text from the API, we can add it to our application. The basics of using the SpeechRecognition interface are fairly straightforward.
By default, you only get one SpeechRecognitionAlternative, but if you want some more alternative results, you can set the maxAlternatives, and maybe compare the confidence levels or present the alternatives to the user. There are other properties available as well where you can change the recognized language or if you want continuous results.
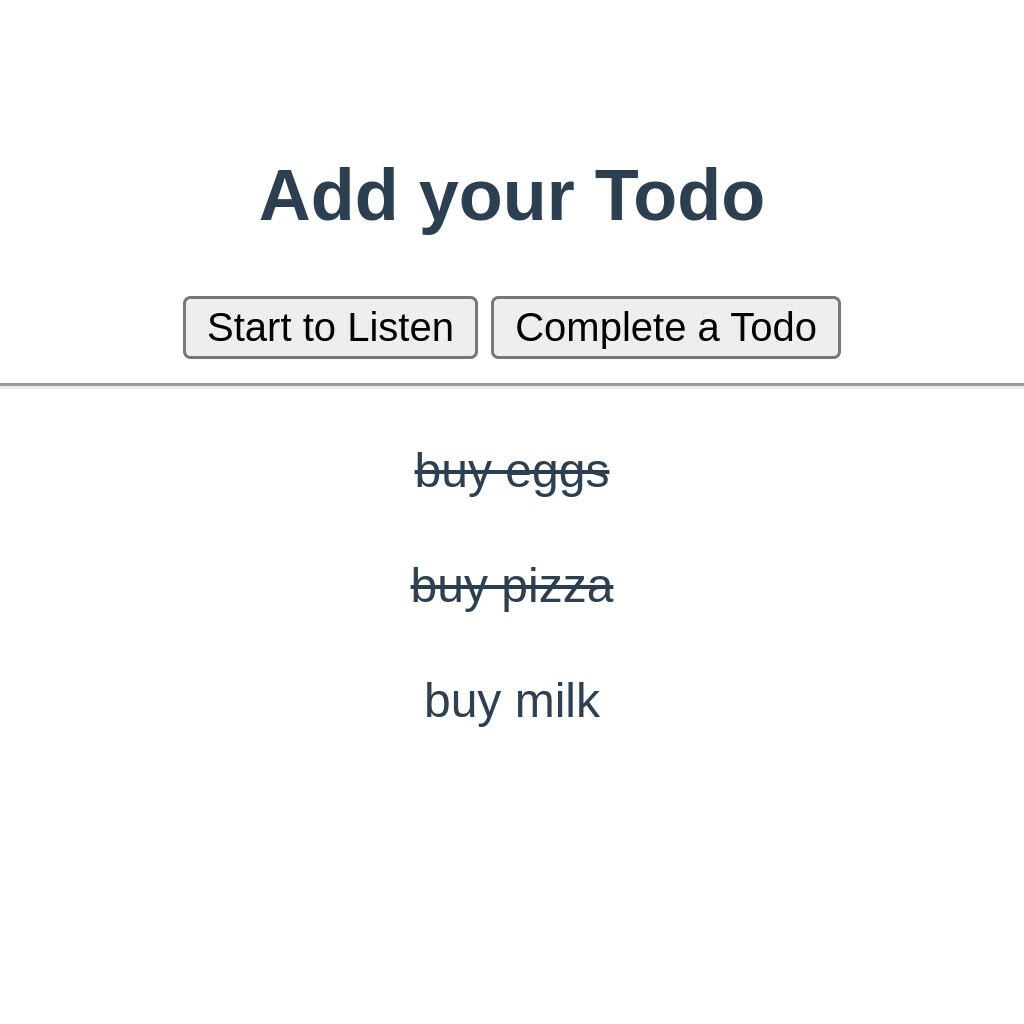
We can even use this same process to mark off Todo items as complete. We can update our current code a bit to find matching Todo items and mark them as complete for us by applying a new CSS class to them.
let doComplete = false;
recognition.addEventListener("result", (event) => {
const result = event.results[0][0].transcript;
if (doComplete) {
const todo = findTodo(result);
todo && completeTodo(todo);
} else {
const todo = createTodo(result);
todo && list.appendChild(todo);
}
recognition.stop();
});
function completeTodo(todoElement) {
todoElement.classList.add("complete");
}What we are doing here is taking the result phrase and searching our list of Todo items to see if there is one that matches. If it matches, we can apply a CSS class that will mark that item as complete!
Text to speech
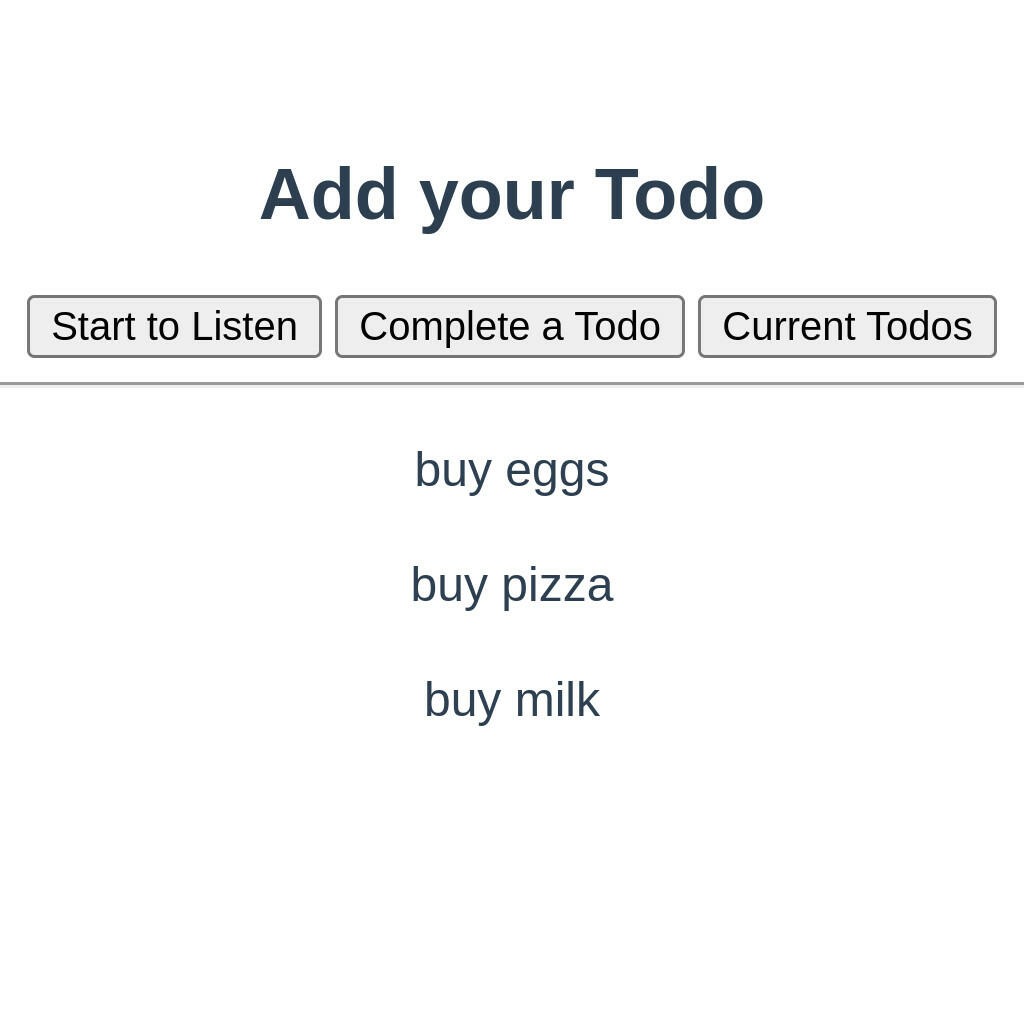
So now we have a way to add and complete items to our Todo app by speaking to it. But can we have the application read our list of Todos back to us? We can use the SpeechSynthesis interface to, surprise surprise, synthesize speech. There are a few ways you can do this, but here is one method you can use to handle speech synthesis.
btnCurrent.addEventListener("click", async () => {
const todos = [...document.querySelectorAll("li")];
for (const todo of todos) {
await speakTodo(todo.innerText);
}
});
async function speakTodo(phrase) {
return new Promise((resolve) => {
let utterance = new SpeechSynthesisUtterance(phrase);
utterance.addEventListener("end", resolve);
synth.speak(utterance);
});
}What we can do is add a button to kick off the whole process. We can find all the Todo elements, and the Todo values. We can use these values to create an array of SpeechSynthesisUtterances. This utterance interface could allow you to use some more advanced features, such as adjusting the pitch, volume, and even the voice you want to speak to you. That preference is all up to you.
We can then iterate over the Todo list using Promises so there is a smooth transition between each utterance. This can help provide a more natural rhythm to the speech.
Example code for this post can be found on GitHub.
Summary
The Web Speech API provides a powerful suite of tools we can use to build some interesting applications. It opens up the opportunity to build more interactive web apps, and to make your application more accessible. There are currently some browser limitations to the interfaces that make up the Web Speech API, and as mentioned there can be some concerns about using the Google web service to process speech to text.
I highly recommend you try the Web Speech API to see what it’s capable of, and what kind of applications you might be inspired to build!